
This chapter describes how to work with labels, decisions and categorical meta-data.
- 4.1. Introduction
- 4.2. Basic handling of labels
- 4.3. Creating labels
- 4.3.1. Label construction by per-sample class names
- 4.3.2. Label construction with unique categories and per-sample indices
- 4.3.2.1. Categories as cell arrays
- 4.3.2.2. Categories as character arrays
- 4.3.2.3. Categories in an sdlist object
- 4.3.3. Label construction by consecutive labeling
- 4.3.4. Labels with one entry per class
- 4.4. Operations on labels
- 4.4.1. Accessing label information
- 4.4.2. Retrieving class sizes and fractions
- 4.4.3. Searching for samples with specific labels
- 4.4.4. Subsets of labels by index
- 4.4.5. Relabeling: Changing class names and defining meta-classes
- 4.4.6. Concatenating label sets
- 4.5. Creating label lists
- 4.5.1. From list of class names
- 4.5.2. Using string prefix
- 4.6. Operations on label lists
- 4.6.1. Accessing list content
- 4.6.2. Converting between names and indices
4.1. Introduction ↩
In perClass, labels, decisions and categorical information is stored in
sdlab objects. In this manual, we refer to one sdlab
object by the plural 'labels'. The sdlab object represents a set
of observations (e.g. data samples). For each sample, it stores its class
name. Unique class names present in a set of observations are accessible
through the label list.
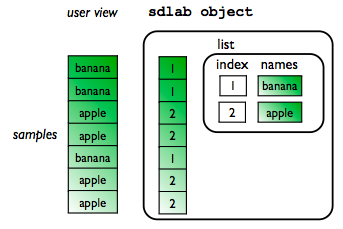
The label list is a table containing all information on concepts represented by the label object. Note, that labels may represent classes to be learned by also patients, or video frames. In general, labels represent categorical meta-data. Each concept (class) has a unique string name. Each entry of the label represents one object. For example, if a label set describes sample class labels, it shows to the user one string per sample. Internally a numerical representation is used to enhance speed when using the label object.
4.2. Basic handling of labels ↩
Set of labels may be constructed by providing the class names per sample:
>> lab=sdlab({'banana','banana','apple','apple','banana'})
sdlab with 5 entries, 2 groups: 'apple'(2) 'banana'(3)
We have created a label object lab holding information on 5 data
samples. The samples are labeled into two classes, 'apple' and 'banana'.
Label objects may be created in many different ways, see Section Creating labels.
Class name in perClass is always a string and is unique within the label set.
In order to view per-sample labels, we may use the getnames method or
the unary plus operator:
>> +lab
ans =
banana
banana
apple
apple
banana
The classes are described in the list object stored within the label set:
>> lab.list
sdlist (2 entries)
ind name
1 apple
2 banana
As we can see, the list has two entries, as two are the concepts described.
In perClass, classes may be always accessed by name or index in the list. For example, we may use the find function to obtain indices of label entries for a specific class:
>> find(lab=='apple')
ans =
3
4
>> find(lab==1)
ans =
3
4
4.3. Creating labels ↩
4.3.1. Label construction by per-sample class names ↩
Label objects may be constructed by providing per-sample string labels in a cell array
>> t={'apple','banana','apple'};
>> lab=sdlab(t)
sdlab with 3 entries, 2 groups: 'apple'(2) 'banana'(1)
or in string array:
>> t=strvcat({'apple','banana','apple'})
t =
apple
banana
apple
>> lab=sdlab(t)
sdlab with 3 entries, 2 groups: 'apple'(2) 'banana'(1)
We may also provide per-sample labels directly into sdlab:
>> lab=sdlab('apple','banana','apple')
sdlab with 3 entries, 2 groups: 'apple'(2) 'banana'(1)
We created a label set for three observations. The set contains two classes (in general called groups), namely 'apple' and 'banana'. Note that for small number of classes, the label set shows also the number of samples available per group.
When given a numerical vector, sdlab converts the numbers into
strings:
>> lab=sdlab([15 10 10 20 15 15])
sdlab with 6 entries, 3 groups: '10'(2) '15'(3) '20'(1)
4.3.2. Label construction with unique categories and per-sample indices ↩
Often, we know what are the uniqie categories and have a vector with an index for each label entry (data sample). We may construct the label object using a general form:
lab = sdlab( uique_categories, vector_of_per_sample_indices )
The unique categories may be defined in several ways.
4.3.2.1. Categories as cell arrays ↩
Unique categories may be provided in a cell array.
>> lab=sdlab({'apple','banana','lemon'},[3 2 2 2 2 2 2 ])
sdlab with 7 entries, 2 groups: 'banana'(6) 'lemon'(1)
>> +lab
ans =
lemon
banana
banana
banana
banana
banana
banana
Note that the resulting label object contains only categories present among
its entries. In our example, there is no 'apple' class in lab.
4.3.2.2. Categories as character arrays ↩
Sometimes, our categories are already represented by a character array:
>> C=strvcat({'apple','banana','lemon'})
C =
apple
banana
lemon
>> class(C)
ans =
char
>> lab=sdlab(C,[3 2 2 2 2 2 2 ])
sdlab with 7 entries, 2 groups: 'banana'(6) 'lemon'(1)
>> +lab
ans =
lemon
banana
banana
banana
banana
banana
banana
4.3.2.3. Categories in an sdlist object ↩
Unique categories are natively described in perClass in an sdlist
object:
>> ll=sdlist('apple','lemon','banana')
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
For detailed information on creating and using sdlist object, see this Section.
We may create a label object by a list and a vector of per-sample indices:
>> lab=sdlab(ll,[1 1 3 2 2 2 2])
sdlab with 7 entries, 3 groups: 'apple'(2) 'lemon'(4) 'banana'(1)
>> +lab
ans =
apple
apple
banana
lemon
lemon
lemon
lemon
Note that sdlab discards class entries not present in the vector
with indexes. This is illustrating the basic principle that sdlab
always contains only classes with at least one sample.
>> lab=sdlab(ll,[3 2 2])
sdlab with 3 entries, 2 groups: 'lemon'(1) 'banana'(2)
>> lab.list
sdlist (2 entries)
ind name
1 lemon
2 banana
Label object may be created from a list as well:
>> lab=sdlab(ll)
sdlab with 3 entries, 3 groups: 'apple'(1) 'lemon'(1) 'banana'(1)
4.3.3. Label construction by consecutive labeling ↩
Often, we need to create labels for sets of observations grouped by
class. For example, we know there are first 3 apples, followed by 2 lemons
and 2 bananas. We may create sdlab object by providing name and count
for each class:
>> lab=sdlab('apple',3,'lemon',2,'banana',2)
sdlab with 7 entries, 3 groups: 'apple'(3) 'lemon'(2) 'banana'(2)
To display the content of the sdlab object, we may use unary plus
operator or getnames function:
>> +lab
ans =
apple
apple
apple
lemon
lemon
banana
banana
It is possible to repeat the class multiple times:
>> lab=sdlab('apple',3,'banana',1,'apple',2)
sdlab with 6 entries, 2 groups: 'apple'(5) 'banana'(1)
>> +lab
ans =
apple
apple
apple
banana
apple
apple
When constructing the consecutive labeling inside Matlab functions, we may directly provide a cell array with unique category names and a vector with class sizes. The 'sizes' option is used to make clear that the vector contains category sizes, not indices:
>> lab=sdlab({'apple','lemon','banana'},'sizes',[3 2 2])
sdlab with 7 entries, 3 groups: 'apple'(3) 'lemon'(2) 'banana'(2)
>> +lab
ans =
apple
apple
apple
lemon
lemon
banana
banana
4.3.4. Labels with one entry per class ↩
Sometimes, we need to create labels for a set of concepts with a single entry per concept. For example, we need to construct labels for 5 clusters. We may provide the base name and index to be appended
>> lab=sdlab('Cluster ',1:5)
sdlab with 5 entries, 5 groups:
'Cluster 1'(1) 'Cluster 2'(1) 'Cluster 3'(1) 'Cluster 4'(1) 'Cluster 5'(1)
We may also provide directly the cluster identifiers, if needed:
>> lab=sdlab('Cluster ',[123 152 182])
sdlab with 3 entries, 3 groups: 'Cluster 123'(1) 'Cluster 152'(1) 'Cluster 182'(1)
4.4. Operations on labels ↩
4.4.1. Accessing label information ↩
Per-sample class names may be accessed using the plus operator or getnames method:
>> lab=sdlab('apple',3,'lemon',2,'banana',2)
sdlab with 7 entries, 3 groups: 'apple'(3) 'lemon'(2) 'banana'(2)
>> getnames(lab)
ans =
apple
apple
apple
lemon
lemon
banana
banana
Handy shortcat for the getnames method is the unary plus (+)
operator. We will get the string content above also using: +lab.
Number of samples is equal to length of the label object:
>> length(lab)
ans =
7
Number of classes present in the label set may be retrieved as a length of the label list:
>> length(lab.list)
ans =
3
Per-sample class indices may be accessed using getindices method
or the unary minus operator:
>> getindices(lab)
ans =
1
1
1
2
2
3
3
>> -lab(1:4)
ans =
1
1
1
2
Label object contains only entries for classes with at least one sample. Empty classes are removed from the list.
4.4.2. Retrieving class sizes and fractions ↩
The sdlab object keeps track of number of sample in each class. Use
getsizes method to retrieve vector of class sizes:
>> getsizes(lab)
ans =
3 2 2
Sizes are presented in the class order defined in the label list:
>> lab.list
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
Related to class sizes are the class fractions accessible via the
fractions field:
>> lab.fractions
ans =
0.4286 0.2857 0.2857
Handy shortcut to list the classes, their sizes and priors is the transpose operator:
>> lab'
ind name size percentage
1 apple 3 (42.9%)
2 lemon 2 (28.6%)
3 banana 2 (28.6%)
4.4.3. Searching for samples with specific labels ↩
The find method helps us to identify indices of label entries assigned to a specific class. There are three ways to retrieve labels:
- by name
- by index of the list
- by regular expressions (i.e. substring)
When we search by name we may use both equal or not-equal operators on labels.
>> find(lab=='banana')
ans =
6
7
% all samples that are not labeled as 'lemon'
>> find(lab~='lemon')
ans =
1
2
3
6
7
In addition to the class name, we may also use relative index in the list:
>> find(lab==3)
ans =
6
7
Regular expression allows for a flexible access to labels. Regular expression is a string describing a pattern matched to the class list. The simplest use is to select classes using a substring. Given these labels:
>> lab'
ind name size percentage
1 B1 31 ( 8.1%)
2 B2 28 ( 7.3%)
3 B20a 24 ( 6.3%)
4 B21a 33 ( 8.7%)
5 B24a 19 ( 5.0%)
6 B24b 21 ( 5.5%)
7 B28 57 (15.0%)
8 B29 26 ( 6.8%)
9 B4 21 ( 5.5%)
10 C3 9 ( 2.4%)
11 C4b 13 ( 3.4%)
12 C4c 15 ( 3.9%)
13 C4d 14 ( 3.7%)
14 C4e 1 ( 0.3%)
15 C4f 14 ( 3.7%)
16 C5a 29 ( 7.6%)
17 C5b 26 ( 6.8%)
To select all classes that contain C5:
>> ind=find(lab=='/C5');
>> lab(ind)
sdlab with 55 entries, 2 groups: 'C5a'(29) 'C5b'(26)
To select the classes that contain C5 or B24:
>> ind=find(lab=='/C5'| lab=='/B24');
>> lab(ind)
sdlab with 95 entries, 4 groups: 'B24a'(19) 'B24b'(21) 'C5a'(29) 'C5b'(26)
4.4.4. Subsets of labels by index ↩
Given a list of sample indices, we can get a subset of the labels:
>> lab
sdlab with 7 entries, 3 groups: 'apple'(3) 'lemon'(2) 'banana'(2)
>> lab(2:5)
sdlab with 4 entries, 2 groups: 'apple'(2) 'lemon'(2)
>> +lab(2:5)
ans =
apple
apple
lemon
lemon
4.4.5. Relabeling: Changing class names and defining meta-classes ↩
The sdrelab function allows us to redefine the labeling by changing the
class names or defining meta-classes. It accepts label object and a cell
array with relabeling rules. Each rule is composed of source and
destination specifier. The source defines the classes to be changed. As
usual, it may be name, (set of) indices or a regular expression. The
destination is a new name of the group defined by source.
For example, lets say we want to handle lemons and bananas together as 'yellow fruit'.
>> lab
sdlab with 7 entries, 3 groups: 'apple'(3) 'lemon'(2) 'banana'(2)
>> lab.list
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
>> lab2=sdrelab(lab,{[2 3] 'yellow fruit'})
1: apple -> apple
2: lemon -> yellow fruit
3: banana -> yellow fruit
sdlab with 7 entries, 2 groups: 'apple'(3) 'yellow fruit'(4)
We have used the indices of 'lemon' and 'banana' classes as the source and 'yellow fruit' as the new class name. Because class name is always unique, we ended up with a single 'yellow fruit' class with four samples.
Multiple rules may be specified in one sdrelab command. Source
specifiers always refer to the original situation in the input data set:
>> lab2=sdrelab(lab,{[2 3] 'yellow fruit' 'apple' 'red fruit'})
1: apple -> red fruit
2: lemon -> yellow fruit
3: banana -> yellow fruit
sdlab with 7 entries, 2 groups: 'red fruit'(3) 'yellow fruit'(4)
We are often interested in a particular class and need to relabel all
remaining classes. To achieve that, we may use the tilde ~ character at
the beginning of the source class name. Such rule will be applied on the
rest of classes:
>> lab2=sdrelab(lab,{'~apple' 'yellow fruit' })
1: apple -> apple
2: lemon -> yellow fruit
3: banana -> yellow fruit
sdlab with 7 entries, 2 groups: 'apple'(3) 'yellow fruit'(4)
You can also use sdrelab to quickly label all samples:
>> lab3=sdrelab(lab,'all','training data')
1: apple -> training data
2: lemon -> training data
3: banana -> training data
sdlab with 260 entries from 'training data'
By default sdrelab shows the translation table. When executed from inside
our routines, we may want to suppress this extra information by adding the
'nodisplay' option:
>> lab2=sdrelab(lab,{'~apple' 'yellow fruit' },'nodisplay')
sdlab with 7 entries, 2 groups: 'apple'(3) 'yellow fruit'(4)
4.4.6. Concatenating label sets ↩
Labels may be concatenated vertically or horizontally.
Vertical concatenation means we are adding labels of other objects.
>> lab1=sdlab('apple',5,'banana',6)
sdlab with 11 entries, 2 groups: 'apple'(5) 'banana'(6)
>> lab2=sdlab('lemon',2,'apple',10)
sdlab with 12 entries, 2 groups: 'lemon'(2) 'apple'(10)
>> L=[lab1; lab2]
sdlab with 23 entries, 3 groups: 'apple'(15) 'banana'(6) 'lemon'(2)
The resulting label set now represent 23 objects of three classes.
Horizontal concatenation appends the class names for the same set of objects. This is useful for construction of unique labels. Lets say we have a data set describing a set of pixels from multiple images. We added an image label to distinguish pixels from different images. We clustered pixels in each image and for each pixel stored the cluster identifier. We have, therefore, 'Cluster 1' label assigned to some pixels in each image. To construct a unique cluster label we use the horizontal concatenation:
% image labels for 20 pixels:
>> lab1=sdlab('Image 1',20)
sdlab with 20 entries from 'Image 1'
% clustering result for the same 20 pixels:
>> lab2=sdlab('Cluster 1',8,'Cluster 2',7,'Cluster 3',5)
sdlab with 20 entries, 3 groups: 'Cluster 1'(8) 'Cluster 2'(7) 'Cluster 3'(5)
>> L=[lab1 lab2]
sdlab with 20 entries, 3 groups: 'Image 1Cluster 1'(8) 'Image 1Cluster 2'(7) 'Image 1Cluster 3'(5)
We may also provide a string separator between the image name and cluster name during the concatenation:
>> L=[lab1 '-' lab2]
sdlab with 20 entries, 3 groups: 'Image 1-Cluster 1'(8) 'Image 1-Cluster 2'(7) 'Image 1-Cluster 3'(5)
The label set L now uniquely identifies the cluster in a specific image.
4.5. Creating label lists ↩
List object sdlist describes a set of concepts. Each concept has a string
name.
4.5.1. From list of class names ↩
List object may be created by providing the class names directly as parameters:
>> ll=sdlist('apple','lemon','banana')
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
or providing the cell array with names:
>> ll=sdlist({'apple','lemon','banana'})
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
Alternative is to use a character array:
>> ll=sdlist(strvcat({'apple','lemon','banana'}))
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
Note that the user-defined order of classes in the list is preserved.
4.5.2. Using string prefix ↩
The sdlist may be also created given prefix string and numbers to be
appended. For example, we want to define a list representing five features:
>> sdlist('Feature ',1:5)
sdlist (5 entries)
ind name
1 Feature 1
2 Feature 2
3 Feature 3
4 Feature 4
5 Feature 5
The prefix string may be also omitted whatsoever:
>> sdlist(1:4)
sdlist (4 entries)
ind name
1 1
2 2
3 3
4 4
4.6. Operations on label lists ↩
4.6.1. Accessing list content ↩
List entries may be retrieved using getnames method or the plus operator:
>> ll
sdlist (3 entries)
ind name
1 apple
2 lemon
3 banana
>> getnames(ll)
ans =
apple
lemon
banana
>> +ll
ans =
apple
lemon
banana
4.6.2. Converting between names and indices ↩
sdlist class provides easy conversion between category names and
their indices:
- ind=ll(name) % convert name into index
- name=ll(ind) % convert index into name
We may convert the per-sample indices into names:
>> ll('lemon')
ans =
2
>> ll(2)
ans =
lemon
Multiple names or indices may be given:
>> ll({'lemon','apple','apple'})
ans =
2
1
1
>> ll([2 1 1])
ans =
lemon
apple
apple
If a non-existent name is used, the conversion routine returns
empty matrix []. If index is out of bounds, an error is raised.