
Keywords: decision tree, random forest, classification speed, PRTools, C4.5
22.1. Introduction ↩
perClass 3.1 has introduced several new classifiers such as decision tree
and random forest. In this article, we focus on the sdtree decision tree
and compare its performance with two state-of-the-art packages, namely C4.5 and PRTools.
Decision tree is a fast discriminant based on recursive thresholding. At each step (node), the threshold is found that yield more homogeneuous solution i.e. separates one or mode classes. For the sake of practical use, the tree needs to be pruned in order to generalize well to unseen data. Therefore, we compere pruned trees for all three packages.
22.2. Experiment 1: Spherical data set ↩
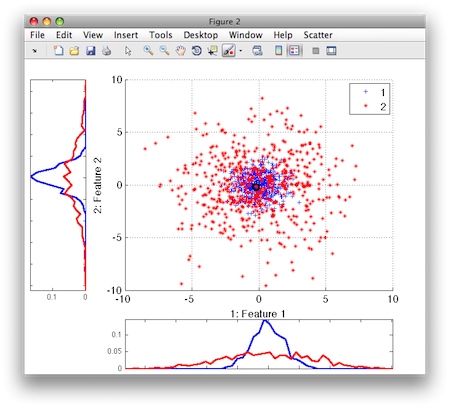
In the first experiment, we used the "spherical" data set generated using
the PRTools gendatc command. The data set consists of two overlapping
Gaussians with different variances in 2D feature space. The Bayes (minimal)
error of this problem is about 0.16.
>> a=gendatc(1000)
Spherical Set, 1000 by 2 dataset with 2 classes: [454 546]
>> sdscatter(a)
22.2.1. Classification error ↩
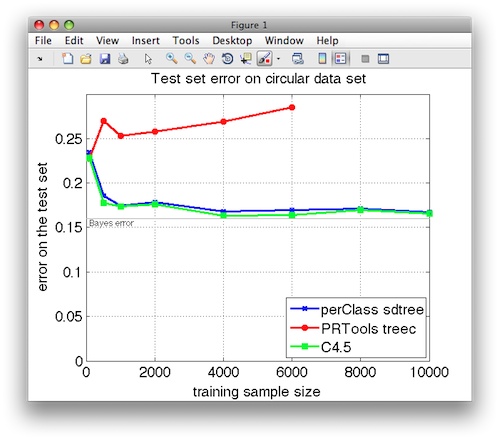
In order to compare different decision tree implementations, we build a learning curve. For a growing number of training data samples, we train the decision tree classifier using the three packages and estimate its error on an independent test set with 10000 samples.
The following image shows the test set error:
In case of perClass, we trained sdtree using default settings
i.e. pruning using internal 80%/20% data split to estimate error.
The PRTools treec classifier was trained using the pruning as follows:
w=treec(tr,'maxcrit',-1). Because treec crashed for 2000 or more
samples using the default recursion limit of Matlab, we inscreased it using
set(0,'RecursionLimit',2000). However, also the increased limit was not
sufficient for data sets with 8000 and 10000 trainig samples.
The C4.5 was executed using the command line on data sets exported from Matlab. We use the reported test set error based on default pruning.
$ time ./c4.5 -u -f data
We may observe that both perClass and C4.5 exhibit similar behaviour
getting close to the Bayes error. PRTools treec seems to have a
difficulty building a generalizing tree.
The cross-validation of perClass sdtree shows the standard deviation of
mean error lower than 1% (not shown in the plot for the sake of clarity).
22.2.2. Training time ↩
Apart of classification error, the training time is a very important
performance indicator. We have measured the training time using tic/toc
Matlab timer for perClass and PRTools implementations and Unix time
command for C4.5. The results are visualized in the following figure:
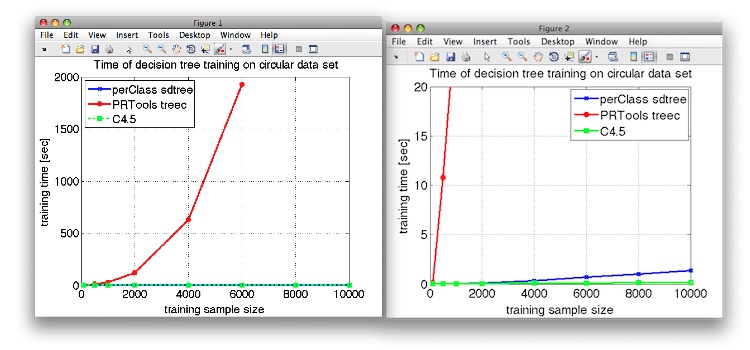
On the left side, we can see that the Matlab decision tree implementation in PRTools exhibits quadratic time complexity with a growing number of samples. In the right figure, we zoomed-in the time axis. It appears that both C-based implementations show linear training complexity. Training on 10000 samples takes less than 1.5 seconds with perClass.
22.3. Experiment 2: Decision tree when increasing feature size ↩
In the second experiment, we investigate how decision trees behave when
increasing the data set dimensionality. We use the "difficult" data set
generated using the PRTools gendatd command.
>> a=gendatd(1000)
Difficult Dataset, 1000 by 2 dataset with 2 classes: [520 480]
>> sdscatter(a)
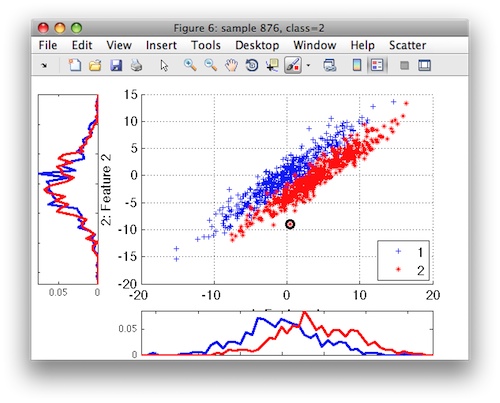
This data set contains two strongly correlated Gaussians. The gendatd
command enables us to increase the number of features by adding
non-informative dimensions. With this data set, we may investiagate how the
decision tree implementations cope with stong correlation and large amount
of noise.
We use 10000 samples for training a separate 10000 samples as a test
set. The perClass sdtree and C4.5 are trained with the default
settings. The test set errors are visualized in the following figure:
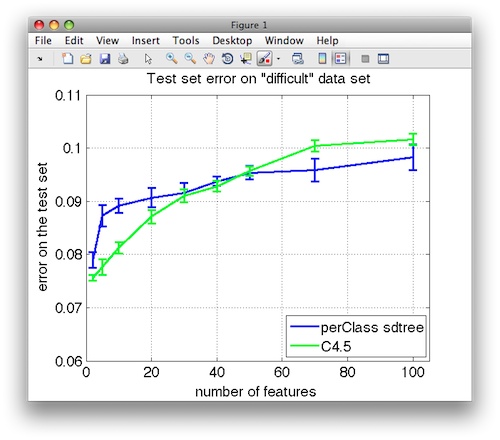
It is interesting to note that both decision tree implementations exhibit different trends when dealing with large number of uninformative features.
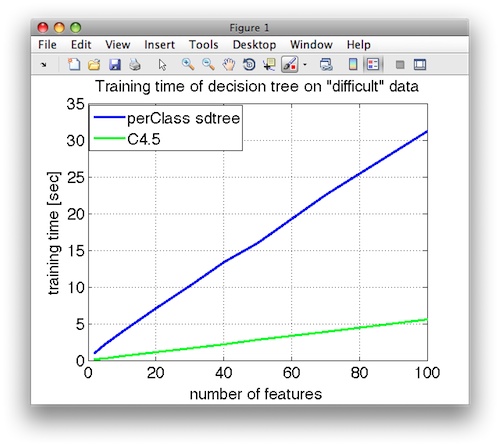
The training time of both implementations is linear when increasing the feature size. Training a decision tree on 10000 samples with 100 features takes 30 seconds for perClass and 5 seconds for C4.5.
22.4. Note on execution speed ↩
Classifier execution speed is of crucial importance for real-time industrial deployment. We have used circular data set with 5000 samples for training and measured the execution speed on a separate set with 100000 samples:
>> a=gendatc(5000)
Spherical Set, 5000 by 2 dataset with 2 classes: [2511 2489]
>> w=treec(a)
Decision Tree, 2 to 2 trained mapping --> tree_map
>> ts=gendatc(100000)
Spherical Set, 100000 by 2 dataset with 2 classes: [49776 50224]
perClass sdtree classifier:
>> p=sdtree(a)
Decision tree pipeline 2x2 (sdp_tree)
>> pd=sddecide(p);
>> tic; dec=ts*pd; toc
Elapsed time is 0.044217 seconds.
PRTools treec classifier:
>> prwarning off
>> prwaitbar off
>> tic; out=ts*w*labeld; toc
Elapsed time is 100.443812 seconds.
We did not find the way to time only the C4.5 execution on new data.
22.5. Conclusions ↩
We have seen that the decision tree implementation, introduced in perClass 3.1, exhibits similar performance to the state-of-the-art C4.5 package and offers similarly high training speed.
The sdtree offers a number of additional options, described in documentation and
is a part of an integrated toolbox which allows, for example, to leverage
powerful feature selection (sdfeatsel), optimize the resulting tree
classifier with ROC analysis (sdroc) or use a tree as a part of a
multiple classifier system (sdrandforest, sdcascade).
In addition, sdtree is built for real-time industrial deployment using
the perClass runtime.
22.5.1. Additional remarks ↩
Experiments were performed using the 64-bit Matlab 2010b (7.11) on a laptop with 2.8 GHz Intel Core 2 Duo and 8GB of memory running Mac OS X 10.5.
The perClass 3.1.2, PRTools 4.2.1 and C4.5 R8 were used.
PRTools was used with prwarning off option to limit textual output.
The C4.5 was compiled using gcc 4.0 with -O2 option.