
Problem: How to define a detector for a class of interest?
Solution: The sddetector command provides a ready to use solution.
Detector is a special type of classifier distinguishing one class of interest from everything else. Training a detector means training a statistical model on the class of interest and adjusting the decision threshold (operating point). There are two principaly different ways of adjusting the threshold, depending on our training data set.
If our training data contains only the class of interest, we adjust the
threshold indirectly by choosing the fraction of training objects to be
rejected. If other classes are present, we may set the threshold to
minimize the classification error. Any detector may be build using the
sddetector command.
Let us build the banana detector, considering the fruit data set.
>> a
'Fruit set' 260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
First, we will consider a data set b containing only banana examples.
>> b=a(:,:,'banana')
'Fruit set' 100 by 2 sddata, class: 'banana'
We provide sddetector with the data set (b), the name of the class of
interest and a model (untrained sdgauss pipeline). Additionally, we
specify the reject fraction of 5%:
>> pd=sddetector(b,'banana',sdgauss,'reject',0.05)
1: banana -> banana
sequential pipeline 2x1 'Gaussian model+Decision'
1 Gaussian model 2x1 one class, 1 component (sdp_normal)
2 Decision 1x1 thresholding on banana at op 1 (sdp_decide)
We will visualize the detector decisions on the data set b:
>> sdscatter(b,pd)
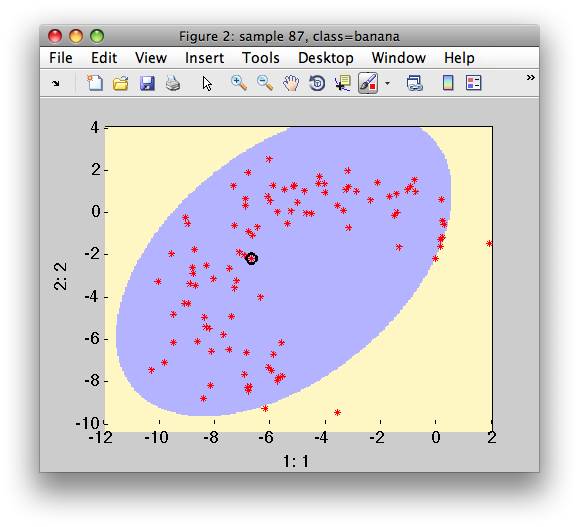
Comparing labels of the data set b with the detector decisions will show
us that 5 of the 100 objects are rejected:
>> sdconfmat(b.lab,b*pd)
ans =
True | Decisions
Labels | banana non-ba | Totals
-------------------------------------
banana | 95 5 | 100
-------------------------------------
Totals | 95 5 | 100
Alternatively, if our data set contains examples from other classes, we may
use them to set the detector threshold. We now train the detector on the
complete data set a, not specifying the reject fraction:
>> pd=sddetector(a,'banana',sdgauss)
1: apple -> non-banana
2: banana -> banana
3: stone -> non-banana
sequential pipeline 2x1 'Gaussian model+Decision'
1 Gaussian model 2x1 one class, 1 component (sdp_normal)
2 Decision 1x1 thresholding ROC on banana at op 28 (sdp_decide)
>> sdscatter(a,pd)
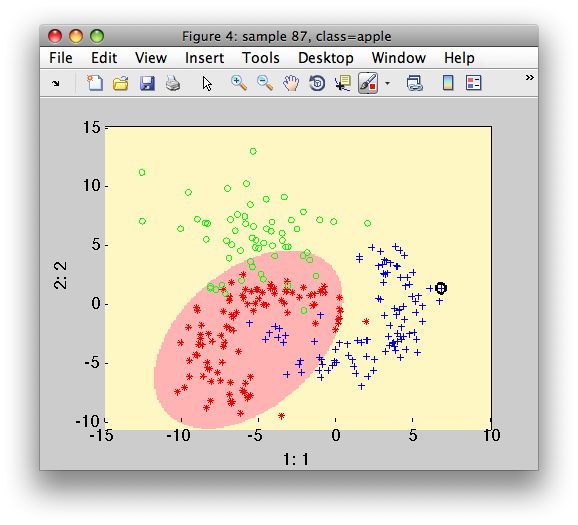
>> sdconfmat(a.lab,a*pd)
ans =
True | Decisions
Labels | banana non-ba | Totals
-------------------------------------
apple | 15 85 | 100
banana | 97 3 | 100
stone | 17 43 | 60
-------------------------------------
Totals | 129 131 | 260
When an additional class or classes are present, sddetector relabels them
creating the non-target class (called 'non-banana' by default). The
detector threshold is then fixed to minimize the mean error between target
and non-target classes using ROC analysis.
The advantage of this approach is that the operating point of the trained detector may be adjusted according to our specific needs later.
The ROC characteristic, stored in our detector pd:
>> pd.roc
ROC (52 thr-based op.points, 3 measures), curop: 33
est: 1:err(banana)=0.10, 2:err(non-banana)=0.06, 3:mean-error=0.08
>> sddrawroc(pd)
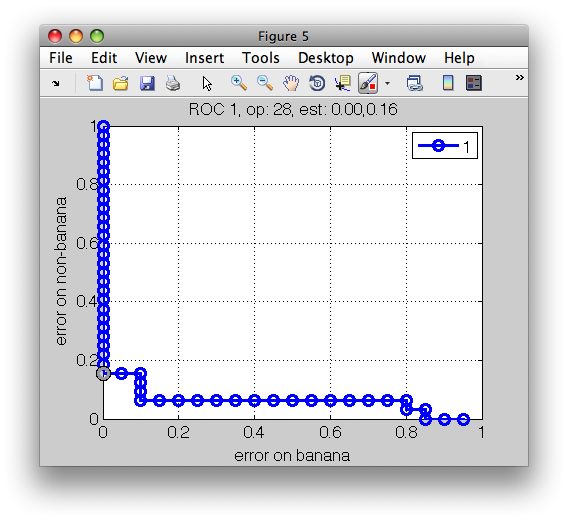
We may select a different operating point in the ROC figure and save the detector back in the workspace by pressing the 's' key:
>> Setting the operating point 33 in sdppl object pd
sequential pipeline 2x1 'Gaussian model+Decision'
1 Gaussian model 2x1 one class, 1 component (sdp_normal)
2 Decision 1x1 thresholding ROC on banana at op 33 (sdp_decide)
>> sdconfmat(a.lab,a*pd)
ans =
True | Decisions
Labels | banana non-ba | Totals
-------------------------------------
apple | 12 88 | 100
banana | 88 12 | 100
stone | 9 51 | 60
-------------------------------------
Totals | 109 151 | 260