
Classifiers, table of contents
This section describes neural network classifiers. perClass sdneural
function provides two types of neural networks, namely the feed-forward
(multi-layer perceptron) and radial-basis function (RBF) networks.
The sddeepnet command implements deep convolutional networks.
- 13.6.1. Feed-forward networks
- 13.6.1.1. Adjusting the number of units and iterations
- 13.6.1.2. Details on the process of training
- 13.6.1.3. Data scaling for neural networks
- 13.6.1.4. Continuing the training process
- 13.6.2. Radial-Basis Function (RBF) networks
- 13.6.2.1. Number of units
- 13.6.2.2. Soft outputs per-unit
- 13.6.2.3. Speed and scalability
- 13.6.3. Deep convolutional networks
- 13.6.3.1. Introduction
- 13.6.3.1.1. Installation and GPU support
- 13.6.3.1.2. Deep learning example
- 13.6.3.2. Fine-tuning deep network training
- 13.6.3.3. Defining architecture in a separate cell array
- 13.6.3.4. Details about training process
- 13.6.3.5. Repeatability of training
- 13.6.3.6. Providing custom training/validation sets
- 13.6.3.7. Training without GUI
- 13.6.3.8. Suppressing all display output
- 13.6.3.9. Convolution layer (conv)
- 13.6.3.10. Fully-connected layers
- 13.6.3.11. Batch-normalization layer (bnorm)
- 13.6.3.12. Maximum spatial pooling (mpool)
- 13.6.3.13. Rectified linear unit (relu)
- 13.6.3.14. Dropout (dropout)
- 13.6.3.15. Custom Matconvnet installation
13.6.1. Feed-forward networks ↩
Without any extra option, sdneural trains a feed-forward neural
network. By default, 10 hidden units are used and the optimization runs for
1000 iterations (epochs):
>> load fruit
260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
>> p=sdneural(a)
sequential pipeline 2x1 'Scaling+Neural network'
1 Scaling 2x2 standardization
2 Neural network 2x3 10 units
3 Decision 3x1 weighting, 3 classes
>> sdscatter(a,p)
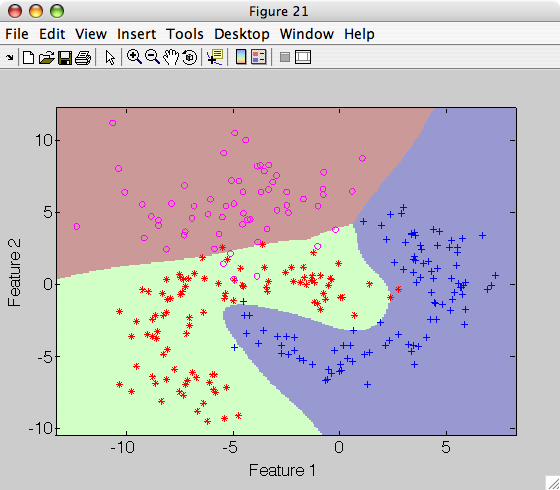
The provided data set is split into training and validation subsets
(80%/20% by default). The training subset is used in optimization and the
validation subset to estimate the generalization error. The validation
fraction may be changed using tsfrac option. Eventually, sdneural
returns the network with lowest mean square error (MSE) on the validation
set. Thanks to this approach the sdneural does not over-fit training data
when trained for a large number of epochs.
13.6.1.1. Adjusting the number of units and iterations ↩
The number of units may be adjusted with 'units' option and number of iterations with 'iters' option:
>> a
'medical D/ND' 5762 by 10 sddata, 2 classes: 'disease'(1495) 'no-disease'(4267)
>> p=sdneural(a,'units',30,'iters',5000)
sequential pipeline 10x1 'Scaling+Neural network'
1 Scaling 10x10 standardization
2 Neural network 10x2 30 units
3 Decision 2x1 weighting, 2 classes
13.6.1.2. Details on the process of training ↩
sdneural provides detailed information on training process as the second output parameter:
>> a
'Fruit set' 260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
>> [p,res]=sdneural(a,'units',20)
sequential pipeline 2x1 'Scaling+Neural network'
1 Scaling 2x2 standardization
2 Neural network 2x3 20 units
3 Decision 3x1 weighting, 3 classes
res =
units: 20
rate: 0.3000
momentum: 0.8000
bestiter: 969
bestEts: 0.0295
Etr: [1x1000 double]
Ets: [1x1000 double]
The res.Etr and res.Ets fields contain training and test mean square error during the optimization process.
>> figure; plot(res.Etr)
>> hold on; plot(res.Ets,'r.')
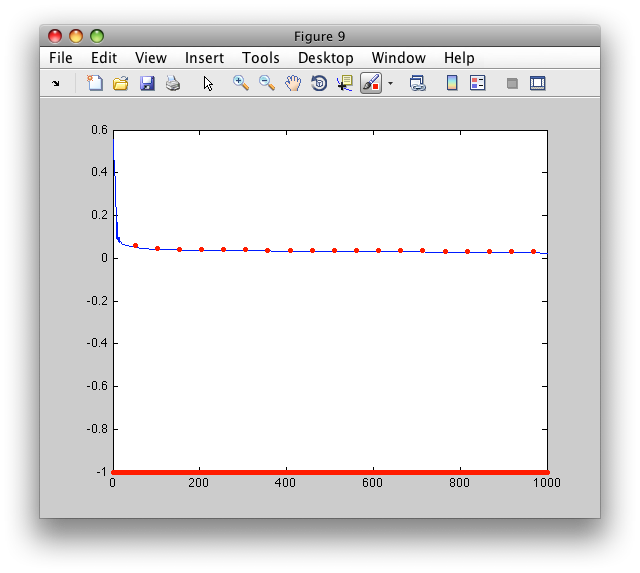
We may observe that the test error is not estimated for each iteration. The step is controlled by the 'test each' option. By default, 100 is used.
13.6.1.3. Data scaling for neural networks ↩
It is useful to scale the training data set passed to sdneural to avoid
long optimization process (the network does not need to learn the scaling).
Therefore, by default sdneural performs scaling using sdscale.
In some situations we may wish to disable this internal scaling. For example, we scale the data ourselves. We may disable scaling using 'no scale' option.
>> p=sdneural(a,'no scale')
sequential pipeline 2x1 'Neural network'
1 Neural network 2x3 10 units
2 Decision 3x1 weighting, 3 classes
13.6.1.4. Continuing the training process ↩
Neural networks belong to algorithms that may be trained further. This is useful for on-line training where more labeled training examples are available later.
Training a network only for 10 iterations does not yield a good classifier:
>> a
'Fruit set' 260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
>> p=sdneural(a,'units',20,'iters',10)
sequential pipeline 2x1 'Scaling+Neural network'
1 Scaling 2x2 standardization
2 Neural network 2x3 20 units
3 Decision 3x1 weighting, 3 classes
>> sdscatter(a,p)
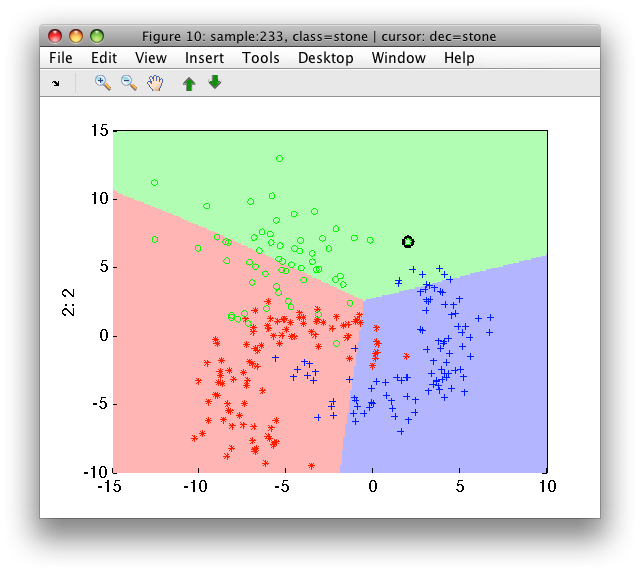
The sdneural can be initialized by an existing neural network pipeline
provided with the 'init' option:
>> p2=sdneural(a,'init',p,'iters',2000)
{??? Error using ==> sdneural at 115
Neural pipeline action expected, got 'Decision'. Provide only the neural step.
The error is caused by the fact, that the pipeline p contains the entire
classifier including scaling and decision steps. We need to pass only the
neural network model, i.e. only the second step of the pipeline p:
>> p2=sdneural(a * p(1),'init',p(2),'iters',2000,'no scale')
sequential pipeline 2x1 'Scaling+Neural network'
1 Scaling 2x2 standardization
2 Neural network 2x3 20 units
3 Decision 3x1 weighting, 3 classes
>> sdscatter(a,p2)
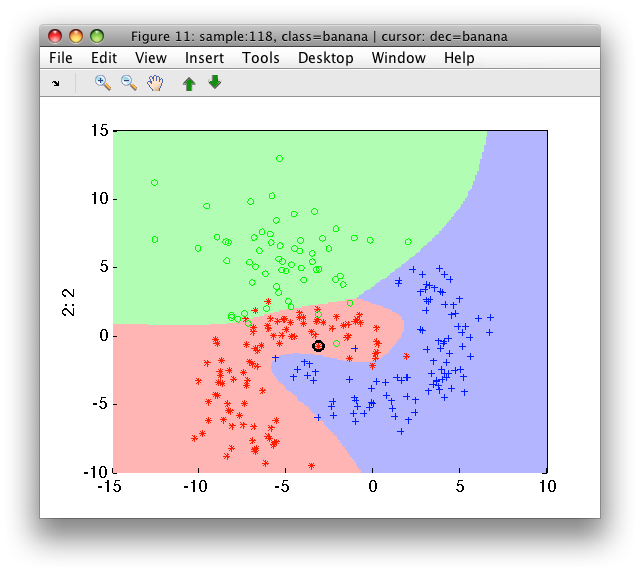
Note, that because our classifier p contained the scaling step, we must
also make sure the data passed to the network for further training is
identically scaled. Therefore, we provide the scaled data set a*p(1) as
the training set. Also, we disable scaling with 'no scale' option.
An alternative is, of course, to scale our data set outside and switch off scaling in all network training using the 'no scale' option.
13.6.2. Radial-Basis Function (RBF) networks ↩
RBF networks use Gaussian radial-basis activation functions in a single
hidden layer. They can be trained using the 'rbf' option of sdneural. By
default, 5 units per class are used:
>> a
'Fruit set' 260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
>> p=sdneural(a,'rbf')
['apple' 5 centers] ['banana' 5 centers] ['stone' 5 centers]
sequential pipeline 2x1 'RBF network+Decision'
1 RBF network 2x3 15 units
2 Decision 3x1 weighting, 3 classes
>> sdscatter(a,p)
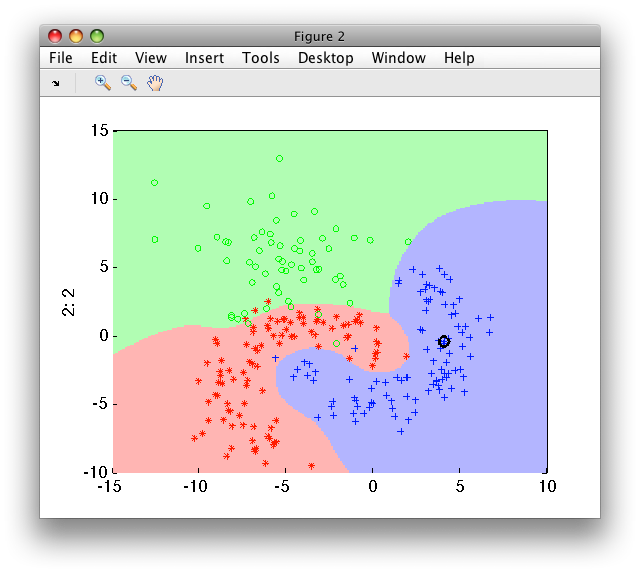
13.6.2.1. Number of units ↩
The number of units may be specified directly after the 'rbf' option:
>> p=sdneural(a,'rbf',10)
['apple' 10 centers] ['banana' 10 centers] ['stone' 10 centers,removing 1 ]
sequential pipeline 2x1 'RBF network+Decision'
1 RBF network 2x3 29 units
2 Decision 3x1 weighting, 3 classes
Alternatively, the 'units' option may be used: sdneural(data,'units',10).
Different number of units may be specified for each class with a vector:
>> a
'Fruit set' 260 by 2 sddata, 3 classes: 'apple'(100) 'banana'(100) 'stone'(60)
>> p=sdneural(a,'rbf',[5 5 1])
['apple' 5 centers] ['banana' 5 centers] ['stone' 1 centers]
sequential pipeline 2x1 'RBF network+Decision'
1 RBF network 2x3 11 units
2 Decision 3x1 weighting, 3 classes
13.6.2.2. Soft outputs per-unit ↩
In order to extract per-unit soft output, use the 'partial' option:
>> p=sdneural(a,'rbf',[5 5 1],'partial')
['apple' 5 centers] ['banana' 5 centers] ['stone' 1 centers]
RBF network pipeline 2x11 11 units
The 11 outputs now correspond to 11 units. With sdscatter(a,p), we may
see all per-unit outputs (use cursor keys).
13.6.2.3. Speed and scalability ↩
sdneural implements a direct formulation of RBF training algorithm which
is suitable to large data sets.
Although RBF network is superficially similar to Parzen classifier or the Gaussian mixture model, computation of RBF kernels allows us to directly apply it to high-dimensional data. In the following example, we train RBF network on hyperspectral data set classifying four types of potato tissue:
>> tr
37967 by 103 sddata, 4 classes: 'rot'(10066) 'green'(3062) 'peel'(12025) 'flesh'(12814)
>> tic; p=sdneural(tr,'rbf',10), toc
['rot' 10 centers] ['green' 10 centers] ['peel' 10 centers] ['flesh' 10 centers]
sequential pipeline 103x1 'RBF network+Decision'
1 RBF network 103x4 40 units
2 Decision 4x1 weighting, 4 classes
Elapsed time is 121.792478 seconds.
Two minute training for a data with 37k samples and 103 dimensions is not too long (2.8 GHz Intel Core 2 Duo CPU).
13.6.3. Deep convolutional networks ↩
13.6.3.1. Introduction ↩
perClass includes support for deep convolutional networks trained using
sddeepnet command. It is built on top of Matconvnet toolbox. It allows to
train classifiers on image data. As perClass bundles Matconfnet build,
there is no extra installation step needed to use deep learning.
13.6.3.1.1. Installation and GPU support ↩
By default, optimizer binaries are built with CPU support that works on all
platforms. To use GPU, one needs Parallel Computing Toolbox and NVIDIA
graphics card supporting CUDA. When invoking sddeepnet command for the
first time on supported platforms, the mex binaries with GPU in
perclass_install_dir/matconvnet/matlab/mex.gpu are put on Matlab path. As
of perClass 5.1 this holds for Linux 64bit.
It is also possible to point sddeepnet to custom-built matconvnet
binaries with matconvnet option. The path provided should point to a
directory where matlab/mex and matlab/simplenn directories are located.
To find out exactly what binary build of matconvnet is used, check Matlab
path after first call to sddeepnet.
13.6.3.1.2. Deep learning example ↩
The data sets for training provide images, reshaped to the same image
size. Therefore, each data set feature corresponds to one pixel. The data
set is supposed to contain the imsize data property specifying the image
height, image width and, optionally, the number of channels.
For example, we may use the nist16 data set that contains hand-written
digits, re-scaled to 16x16 raster. Therefore, it has 256 features:
>> load nist16.mat
>> a
'Nist 16' 2000 by 256 sddata, 10 classes: [200 200 200 200 200 200 200 200 200 200]
>> a'
'Nist 16' 2000 by 256 sddata, 10 classes: [200 200 200 200 200 200 200 200 200 200]
sample props: 'lab'->'class' 'class'(L)
feature props: 'featlab'->'featname' 'featname'(L)
data props: 'data'(N) 'imsize'(N)
>> a.imsize
ans =
16 16
Note: If your data set does not contain the 'imsize' property, you may add
it with setprop. Note the 'data' option in the end: It is
needed as the 'imsize' property is a property of the entire data set.
>> a=setprop(a,'imsize',[16 16],'data')
'Nist 16' 2000 by 256 sddata, 10 classes: [200 200 200 200 200 200 200 200 200 200]
We split the data into training and test subsets:
>> [tr,ts]=randsubset(a,0.5)
'Nist 16' 1000 by 256 sddata, 10 classes: [100 100 100 100 100 100 100 100 100 100]
'Nist 16' 1000 by 256 sddata, 10 classes: [100 100 100 100 100 100 100 100 100 100]
When we pass the training data to sddeepnet, we receive an error message
reminding us that the network architecture needs to be specified. The input
image listed is of 16x16x1 size:
>> p=sddeepnet(tr)
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. ? : 16x16x1
ERROR: Undefined network architecture. Define layers starting with a
convolution. Provide kernel size, filter bands and number of filters (outputs).
Example: 'conv',[3 3 1 10] means 3x3x1 filter, 10 times.
We may add layers directly in the sddeepnet command. First, we wish to
add a convolutional layer with 5x5 kernel on the one input channel. We want
to train 10 such filters. Therefore, we add:
>> p=sddeepnet(tr,'conv',[5 5 1 10])
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
^^^^^^^^
Architecture definition INCOMPLETE as the last output must be 1x1x10 (for the 10 class problem)
Incomplete architecture definition
You can see, that sddeepnet command shows us, for each layer of the
network, the sizes of input and output image and filter details. The
architecture is still incomplete, because we need to go down to 1x1x(number
of classes), in our case 10.
We will add other layers. After convolution, it is very useful to include the 'batch normalization' layer. This significantly speeds up training process. Later, we include spatial pooling ('mpool' that stands for max pooling) with 3x3 kernel and rectified linear unit ('relu'):
>> p=sddeepnet(tr,'conv',[5 5 1 10],'bnorm','mpool',3,'relu')
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
^^^^^^^^
Architecture definition INCOMPLETE as the last output must be 1x1x10 (for the 10 class problem)
Incomplete architecture definition
We're at 10x10x10 feature map (image). Therefore, we include e.g. other layers:
>> p=sddeepnet(tr,'conv',[5 5 1 10],'bnorm','mpool',3,'relu','conv',[5 5 10 20],'bnorm','mpool',2,'relu','conv',[5 5 20 10])
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
Specify number of epochs with 'epochs' option
The architecture is now complete, as we have 1x1x10 output. We can specify the number of training epochs and execute the training.
>> p=sddeepnet(tr,'conv',[5 5 1 10],'bnorm','mpool',3,'relu','conv',[5 5 10 20],'bnorm','mpool',2,'relu','conv',[5 5 20 10],'epoch',20)
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
sequential pipeline 256x1 'DeepNet (best,iter 12)'
1 Convolution 256x1440 10 filters 5x5 on 16x16x1 image
2 Batch normalization 1440x1440 on 12x12x10 image
3 Max pooling 1440x1000 on 12x12x10 image
4 Relu 1000x1000
5 Convolution 1000x720 20 filters 5x5 on 10x10x10 image
6 Batch normalization 720x720 on 6x6x20 image
7 Max pooling 720x500 on 6x6x20 image
8 Relu 500x500
9 Convolution 500x10 10 filters 5x5 on 5x5x20 image
10 Decision 10x1 weighting, 10 classes
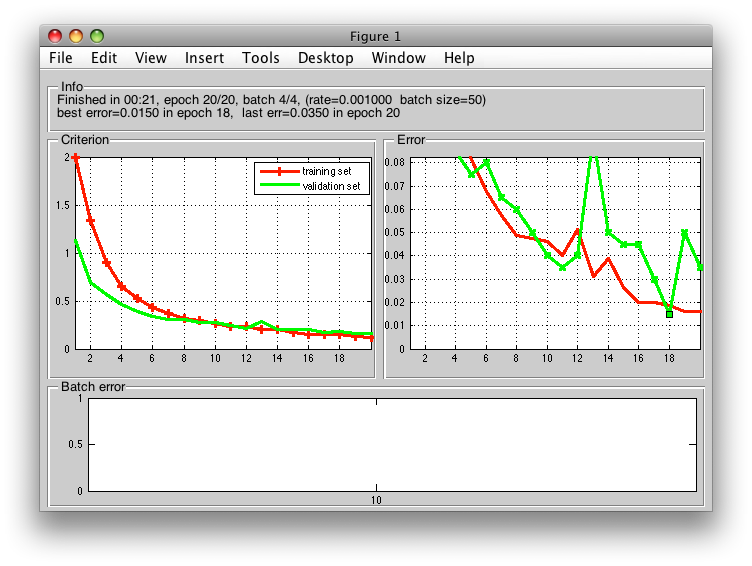
During training, a GUI figure shows progress. In the upper part, information such as epoch, batch and training settings (rate/batch size) are noted. The best validation-set error is also shown. In the middle part, we can see optimized criterion on the left and error on the right side, each with training set error in red and validation set error in green. The best validation-set result so far, is highlighted. This is also the solution returned form the network.
In the bottom part of the GUI figure is shown the progress in terms of batches (training in red, validation in green).
The sddeepnet returns a standard perClass pipeline that can be directly
applied to any data set with correct number of features (in out case 256).
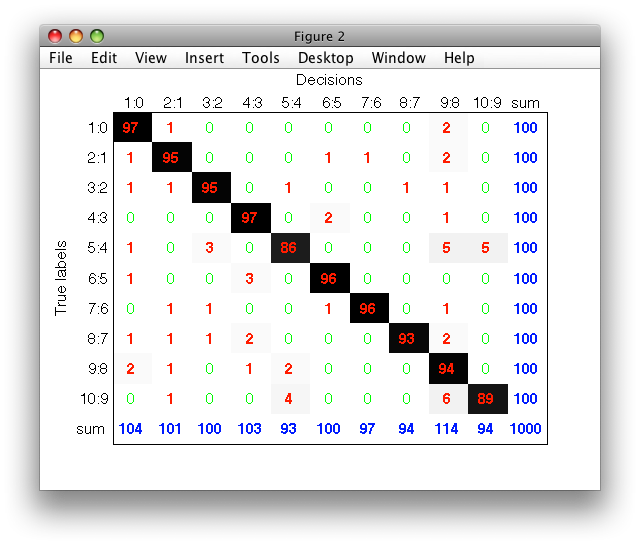
>> dec=ts*p
sdlab with 1000 entries, 10 groups
>> sdconfmat(ts.lab,dec,'figure')
13.6.3.2. Fine-tuning deep network training ↩
Deep network training may be continued for more iterations or with other training settings such as learning rate ('rate' option) or batch size ('batch' option). In our example, we simply train the network for another 20 epochs:
>> p2=sddeepnet(tr,'init',p,'epoch',20)
sequential pipeline 256x1 'DeepNet (best,iter 19)'
1 Convolution 256x1440 10 filters 5x5 on 16x16x1 image
2 Batch normalization 1440x1440 on 12x12x10 image
3 Max pooling 1440x1000 on 12x12x10 image
4 Relu 1000x1000
5 Convolution 1000x720 20 filters 5x5 on 10x10x10 image
6 Batch normalization 720x720 on 6x6x20 image
7 Max pooling 720x500 on 6x6x20 image
8 Relu 500x500
9 Convolution 500x10 10 filters 5x5 on 5x5x20 image
10 Decision 10x1 weighting, 10 classes
>> dec=ts*p2
sdlab with 1000 entries, 10 groups
% original network
>> sdtest(ts,p)
ans =
0.0620
% improved newtork
>> sdtest(ts,p2)
ans =
0.0460
In our case, we found a better solution.
13.6.3.3. Defining architecture in a separate cell array ↩
sddeepnet accepts architecture defined in a separate cell array. This
allows user to define and comment her architecture in a script file and
results in shorted command lines:
>> A={'conv',[5 5 1 10],...
'bnorm',...
'mpool',3,...
'relu',...
'conv',[5 5 10 20],...
'bnorm',...
'mpool',2,...
'relu',...
'conv',[5 5 20 10] };
>> p=sddeepnet(tr,'arch',A,'epoch',20)
13.6.3.4. Details about training process ↩
As the second argument, sddeepnet provides detailed information about the
training process.
>> [p,res]=sddeepnet(tr,'arch',A,'epoch',20);
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
>> res
res =
timestamp: '21-Sep-2016 13:26:59'
best: [256x1 sdppl]
bestiter: 16
bestEts: 0.0400
last: [256x1 sdppl]
lastiter: 20
lastEts: 0.0550
Etr: [1x20 single]
Ets: [1x20 single]
The res structure provides:
best- Best model find (same as first argument returned)bestiter- Iteration at which the best model was foundbestEts- Test set error of the best modellast- Last model optimized (sometimes, we might want to refine that hopefully well-trained model further)lastiter- Last iterationlastEts- Test set error of the last model foundEts- per-epoch error on the training set (red line in the GUI)Ets- per-epoch error on the test set (green line in the GUI)
13.6.3.5. Repeatability of training ↩
In order to make sddeepnet training repeatable, fix the random seed.
This will make sure that exactly the same data splits are used internally.
>> rand('state',1); [p,res]=sddeepnet(tr,'arch',A,'epoch',20);
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
>> res.Ets
ans =
Columns 1 through 7
0.2900 0.2100 0.1350 0.1300 0.0900 0.0900 0.0950
Columns 8 through 14
0.0850 0.0900 0.0550 0.0750 0.0650 0.0750 0.0650
Columns 15 through 20
0.0550 0.0600 0.0600 0.0500 0.0550 0.0450
>> rand('state',1); [p,res]=sddeepnet(tr,'arch',A,'epoch',20);
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
>> res.Ets
ans =
Columns 1 through 7
0.2900 0.2100 0.1350 0.1300 0.0900 0.0900 0.0950
Columns 8 through 14
0.0850 0.0900 0.0550 0.0750 0.0650 0.0750 0.0650
Columns 15 through 20
0.0550 0.0600 0.0600 0.0500 0.0550 0.0450
13.6.3.6. Providing custom training/validation sets ↩
It is possible to provide custom training and validation sets split externally.
In the example below, we use a simple random subset. In practice, we may want to split not randomly, but based on a specific label e.g. making sure that validation examples originate from different set of images that training examples.
>> tr
1000 by 256 sddata, 10 classes: [100 100 100 100 100 100 100 100 100 100]
>> rand('state',1); [tr2,val2]=randsubset(tr,20)
200 by 256 sddata, 10 classes: [20 20 20 20 20 20 20 20 20 20]
800 by 256 sddata, 10 classes: [80 80 80 80 80 80 80 80 80 80]
>> rand('state',1); [p,res]=sddeepnet(tr2,'test',val2,'arch',A,'epoch',20,'nogui')
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
Training (20 epochs):
1:besterr=0.7000 2:remaining time: 00:05
2:besterr=0.5612
3:besterr=0.4800 4:remaining time: 00:04
4:besterr=0.4212
5:besterr=0.3812 6:remaining time: 00:04
6:besterr=0.3288
7:besterr=0.3137 8:remaining time: 00:03
8:besterr=0.2950
9:besterr=0.2862 10:remaining time: 00:03
10:besterr=0.2713
11:besterr=0.2600 12:remaining time: 00:02
12:besterr=0.2362
13:besterr=0.2313 14:remaining time: 00:02
14:besterr=0.2237
15:besterr=0.2075 16:remaining time: 00:01
16:besterr=0.2013
17:besterr=0.1863 18:remaining time: 00:01
18:besterr=0.1713
19:besterr=0.1663 20:remaining time: 00:00
Finished in 00:06, after 20 epochs, (rate=0.001000 batch size=50)
best error=0.1663 in epoch 19, last err=0.1688 in epoch 20
13.6.3.7. Training without GUI ↩
We may suppress opening the GUI window while training with 'nogui' option. Details on the training process are then displayed in the command window. Each time a new best error on the test set is reached, it will be displayed in the left-most column. In this way, we have a quick overview of training progress.
Each 10% of epochs, an estimated remaining training time is displayed.
Summary information is provided at the end.
>> [p,res]=sddeepnet(tr,'arch',A,'epoch',20,'nogui')
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x10 5x5x1 10 1
2. 'bnorm' : 12x12x10 12x12x10
3. 'mpool' : 12x12x10 10x10x10 3x3 1
4. 'relu' : 10x10x10 10x10x10
5. 'conv' : 10x10x10 6 x6 x20 5x5x10 20 1
6. 'bnorm' : 6 x6 x20 6 x6 x20
7. 'mpool' : 6 x6 x20 5 x5 x20 2x2 1
8. 'relu' : 5 x5 x20 5 x5 x20
9. 'conv' : 5 x5 x20 1 x1 x10 5x5x20 10 1
Architecture OK
Training (20 epochs):
1:besterr=0.2900 2:remaining time: 00:09
2:besterr=0.2100
3:besterr=0.1350 4:remaining time: 00:08
4:besterr=0.1300
5:besterr=0.0900 6:remaining time: 00:08 8:remaining time: 00:07
8:besterr=0.0850 10:remaining time: 00:05
10:besterr=0.0550 12:remaining time: 00:04 14:remaining time: 00:03 16:remaining time: 00:02
18:besterr=0.0500 20:remaining time: 00:00
20:besterr=0.0450
Finished in 00:11, after 20 epochs, (rate=0.001000 batch size=50)
best error=0.0450 in epoch 20, last err=0.0450 in epoch 20
13.6.3.8. Suppressing all display output ↩
It is possible to disable display output with 'nodisplay' option:
>> [p,res]=sddeepnet(tr,'arch',A,'epoch',20,'nogui','nodisplay');
>>
13.6.3.9. Convolution layer (conv) ↩
- parameter:
[w h c o]- kernel width, height, number of inputs, number of outputs (i.e. number of filters to train)- alternatively, a step may be given as the 5th element:
[w h c o s]
- alternatively, a step may be given as the 5th element:
Convolution layer implements a filter sliding through the input image.
The filter is a 3D matrix, width x height x number of channels. Only square kernels (width = height) are supported in perClass 5. The fourth parameter specifies how many filters are to be trained. Optionally, a fifth parameter may be provided specifying a step within the input image.
Convolution filters may be defined in two ways:
A. Use the same number of channels as the outputs of the previous layer.
Example:
>> p=sddeepnet(tr,'conv',[5 5 1 15],'bnorm','mpool',3,'relu','conv',[5 5 15 20]...
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x15 5x5x1 15 1
2. 'bnorm' : 12x12x15 12x12x15
3. 'mpool' : 12x12x15 10x10x15 3x3 1
4. 'relu' : 10x10x15 10x10x15
5. 'conv' : 10x10x15 6 x6 x20 5x5x15 20 1
... ^^
The fifth layer uses kernel 5x5x15 with 15 channels, because previous layer provides 15 outputs.
B. Use smaller number of channels than outputs of the previous layer.
In this setup, "filter groups" are formed. The number of outputs of the previous layer must be divisible by the number of channels we request.
>> p=sddeepnet(tr,'conv',[5 5 1 15],'bnorm','mpool',3,'relu','conv',[5 5 3 20]...
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x15 5x5x1 15 1
2. 'bnorm' : 12x12x15 12x12x15
3. 'mpool' : 12x12x15 10x10x15 3x3 1
4. 'relu' : 10x10x15 10x10x15
5. 'conv' : 10x10x15 6 x6 x20 5x5x3 20 1 5 filter groups (each 4 filters)
... ^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
The fifth layer defines 5x5x3 filter. The output of previous layer is 15 which is divisible by 3. Therefore, we will obtain 5 filters groups (15/3).
Note, that the number of outputs of the fifth group must be a multiple of 5. In our example, it is OK because we ask for 20 outputs. Therefore, we will have 4 filters per group (20 outputs/5 groups).
Filters F1,F2,F3 and F4 are trained on the first three outputs of the previous layer. The the filters F5,F6,F7 and F8 are trained on outputs 4:6 of the previous layer and so on.
In case the number of outputs cannot be divided by the number of filter groups, we receive an error:
>> p=sddeepnet(tr,'conv',[5 5 1 15],'bnorm','mpool',3,'relu','conv',[5 5 3 18]...
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x15 5x5x1 15 1
2. 'bnorm' : 12x12x15 12x12x15
3. 'mpool' : 12x12x15 10x10x15 3x3 1
4. 'relu' : 10x10x15 10x10x15
5. 'conv' : 10x10x15 6 x6 x18 5x5x3 18 1
... ^^
ERROR: Invalid number of output bands (18) that is not divisible by the number
of filter groups (5)
13.6.3.10. Fully-connected layers ↩
Fully-connected layers are created with 'conv' option making the output size equal to 1x1 pixel.
Example: Here, we use one convolutional layer, pooling and add two fully-connected layers, one with 50 hidden units and the final one with 10 (our number of classes):
>> rand('state',1); p2=sddeepnet(tr,'conv',[5 5 1 15],'mpool',3,'conv',[10 10 15 50],'conv',[1 1 50 10],'epochs',200)
ind acion input -> output : filter count step
----------------------------------------------------------------------------------
1. 'conv' : 16x16x1 12x12x15 5x5x1 15 1
2. 'mpool' : 12x12x15 10x10x15 3x3 1
3. 'conv' : 10x10x15 1 x1 x50 10x10x15 50 1
4. 'conv' : 1 x1 x50 1 x1 x10 1x1x50 10 1
Architecture OK
sequential pipeline 256x1 'DeepNet (best,iter 178)'
1 Convolution 256x2160 15 filters 5x5 on 16x16x1 image
2 Max pooling 2160x1500 on 12x12x15 image
3 Convolution 1500x50 50 filters 10x10 on 10x10x15 image
4 Convolution 50x10 10 filters 1x1 on 1x1x50 image
5 Decision 10x1 weighting, 10 classes
13.6.3.11. Batch-normalization layer (bnorm) ↩
- parameter: none
Batch normalization layer uses statistics of individual batches to re-normalize outputs of the previous convolutional layer. It does not have any parameter and does not alter network geometry.
The convolution and batch normalization layers may be merged with plus operator in order to speed-up execution on new samples:
>> p
sequential pipeline 256x1 'DeepNet (best,iter 3)'
1 Convolution 256x2160 15 filters 5x5 on 16x16x1 image
2 Batch normalization 2160x2160 on 12x12x15 image
3 Max pooling 2160x1500 on 12x12x15 image
4 Relu 1500x1500
5 Convolution 1500x720 20 filters 5x5 on 10x10x15 image
6 Batch normalization 720x720 on 6x6x20 image
7 Max pooling 720x500 on 6x6x20 image
8 Relu 500x500
9 Convolution 500x10 10 filters 5x5 on 5x5x20 image
10 Decision 10x1 weighting, 10 classes
>> p2=p(1)+p(2:5)+p(6:end)
sequential pipeline 256x1 'DeepNet (best,iter 3)'
1 Convolution+bnorm 256x2160 15 filters 5x5 on 16x16x1 image
2 Max pooling 2160x1500 on 12x12x15 image
3 Relu 1500x1500
4 Convolution+bnorm 1500x720 20 filters 5x5 on 10x10x15 image
5 Max pooling 720x500 on 6x6x20 image
6 Relu 500x500
7 Convolution 500x10 10 filters 5x5 on 5x5x20 image
8 Decision 10x1 weighting, 10 classes
13.6.3.12. Maximum spatial pooling (mpool) ↩
- parameter:
b- kernel block size
Maximum pooling uses spatial maximum filter and outputs maximum value of previous-layer outputs in each neighborhood. It is applied independently to each channel.
13.6.3.13. Rectified linear unit (relu) ↩
- parameter: none
Rectified linear unit is a simple transfer function that turns all negative values in zero and lets all positive values pass through. It is known to significantly improve convergence speed.
13.6.3.14. Dropout (dropout) ↩
- parameter: optional probability P (default: 0.5)
Drop out layer is active only in training. It is used to randomly disable some training neurons and so limits over-fitting.
13.6.3.15. Custom Matconvnet installation ↩
Training of sddeepnet convolutional networks is handled by Matcovnet
toolbox. perClass 5 bundles the Matconvnet build with binaries for 64-bit
platforms. Therefore, there is no extra installation step needed in order
to use deep learning in perClass.
However, it is possible to use a custom-built Matconvnet. In order to do
so, use 'noaddpath' option when invoking sddeepnet and add the following
directories of Matconvnet on Matlab path:
If you're not using Mathworks Parallel Computing Toolbox, add these directories to Matlab path:
matconvnet/matlabmatconvnet/matlab/compatibility/parallelmatconvnet/matlab/mexmatconvnet/matlab/simplenn
In case you're using Parallel Computing Toolbox, ommit the compatibility fallback functions in parallel subdirectory and add only the following directories to Matlab path:
matconvnet/matlabmatconvnet/matlab/mexmatconvnet/matlab/simplenn