
Keywords: classifier execution, classifier approximation, neural networks, soft outputs
Problem: How to speed up classifiers using neural network approximation?
Solution: Provide desired classifier soft outputs on the validation set as targets in neural network training.
In practice, we sometimes design a well-performing classifier which is too computationally demanding in execution for a given application. Typically, this holds for non-parametric approaches such as k-NN or Parzen which are capable of modelling complex data distributions. This comes at a high computational cost because all stored training examples (prototypes) are processed each time we execute the non-parametric classifier on a new observation.
In this example, we discuss classifier speedup based on soft output approximation. We adopt neural network as a general approximation tool and use it to model soft outputs of our non-parametric classifier.
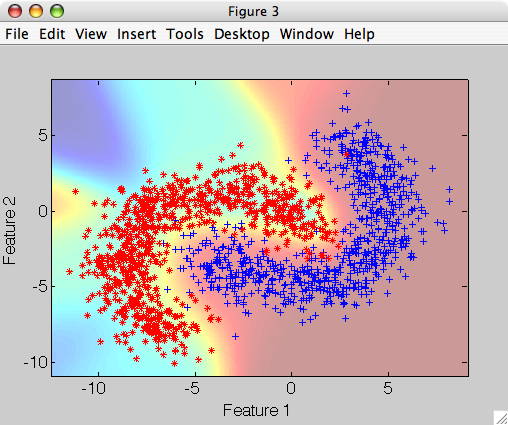
Let us consider two-class banana-shaped data:
>> a=sddata(gendatf(3000)); a=a(:,:,[1 2])
'Fruit set' 200 by 2 sddata, 2 classes: 'apple'(983) 'banana'(1010)
The classes are not linearly separable. Non-parametric Parzen classifier may provide a low-error solution to this problem.
In realistic setting, we will need to split the available labeled data into two parts, using one for training the classifier and the other for validation.
>> [tr,val]=randsubset(a,0.8)
'Fruit set' 100 by 2 sddata, 2 classes: 'apple'(787) 'banana'(814)
'Fruit set' 100 by 2 sddata, 2 classes: 'apple'(196) 'banana'(203)
>> p=sdparzen(tr)
.........
Parzen pipeline 2x2 2 classes, 1601 prototypes (sdp_parzen)
Because we're interested in discrimination between the two classes, we simplify the approximation problem by normalizing the Parzen class outputs to sum to one:
>> p2=p *sdp_norm(2,p.lab)]
sequential pipeline 2x2 'Parzen+Output normalization'
1 Parzen 2x2 2 classes, 1601 prototypes (sdp_parzen)
2 Output normalization 2x2 (sdp_norm)
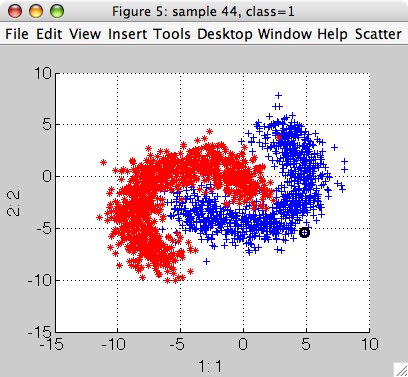
Classifier soft output (posterior) may be visualized using sdscatter:
>> sdscatter(tr,p2)
Now we can compute the soft outputs on our training set:
>> out=tr*p2
Banana Set, 1601 by 2 dataset with 2 classes: [787 814]
And train neural network approximating this soft outputs. We use ten units in hidden layer and train for 10 000 epochs.
>> pn=sdneural(tr,'units',10,'epochs',10000,'targets',+out)
epochs (*100):....................................................................................................
Neural network pipeline 2x2 (sdp_neural)
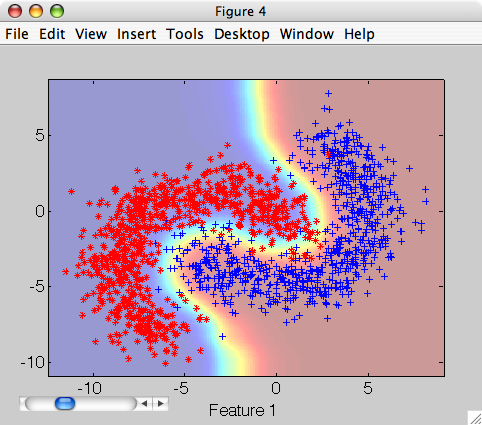
>> sdscatter(tr,pn)
Now we can validate the approximation on the kept-aside validation set:
>> r=sdroc(val*p)
ROC (2001 w-based op.points, 3 measures), curop: 886
est: 1:err(1)=0.02, 2:err(2)=0.02, 3:mean-error=0.02
>> r2=sdroc(val*pn)
ROC (2001 w-based op.points, 3 measures), curop: 1040
est: 1:err(1)=0.02, 2:err(2)=0.03, 3:mean-error=0.02
sdroc command estimates ROC characteristic on the validation set and sets
the operating point by minimizing the mean classification error. For both
classifiers, we obtain comparable mean error of 2%.
Note that for the Parzen, we may skip the output normalization and use the
model p returning class conditional densities.
For execution speed validation, we use a randomly generated dataset with 100 000 samples:
>> data=rand(100000,2);
We construct the complete pipelines combining model and the operating point (obtained using ROC):
>> ppar=p*r
1 sdp_parzen 2x2 2 classes, 1601 prototypes
2 sdp_decide 2x1 Weight-based decision (2 classes, 2001 ops) at op 886
>> pnet=pn*r2
1 sdp_neural 2x2
2 sdp_decide 2x1 Weight-based decision (2 classes, 2001 ops) at op 1040
Now we can measure execution time on 100 000 samples. We use the .*
operator which returns the numerical decision codes:
>> tic; dec=data.*ppar; toc
Elapsed time is 2.604456 seconds.
>> tic; dec=data.*pnet; toc
Elapsed time is 0.064840 seconds.
>> 2.6/0.065
ans =
40
Using the Parzen approximation, we have reached formidable speedup factor of 40. Note that the speed of the neural network approximation is fully determined by the number of hidden units.